Create Cortana Audio Files From Text Using PowerShell
Use Windows 10’s Text-to-Speech capability and Cortana’s voice to create WAV audio from within a PowerShell script.
Finding a Universal Voice: A Universal Problem
Have you ever called a support line and had to listen to a bunch of different recorded scripts, also known as “prompts”? The prompts may be the voice of a single person or a combination of different people (maybe the original voice left the company). There may be feedback noise on the recording. The speaker may have tripped over a word but decided not to record the prompt over again. Maybe the speaker had a cold one the day of recording. All of these factors can create an inconsistent user experience when interacting with the call prompts. If that weren’t enough, it takes TIME to record prompts manually! The more you have the longer it will take, even if you get every recording right on the first try.
Wouldn’t it be great if there was a way to audio files with a consistent voice, and in an efficient manner? We can, with PowerShell and Windows 10’s Text-to-Speech capability, powered by the .NET class SpeechSynthesizer.
Enabling the Microsoft Eva Voice (aka Cortana) in Windows 10
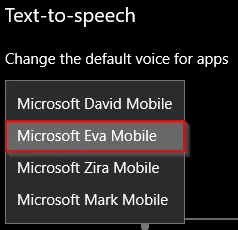
First, we are going to take care of a non-PowerShell prerequisite. By default in Windows 10, you get three Text-to-Speech voices: David, Zira, and Mark. Microsoft is apparently trying to keep Cortana all to themselves. We need to do a little work to enable ‘Eva’, the voice of Cortana.

Default Windows 10 Text-to-Speech Voices
You can read the full instructions for enabling Microsoft Eva in the Windows 10 Creators Update here (superuser.com). It is a good write up with screenshots that doesn’t make sense to reproduce in this post. Note I said Windows 10 Creators Update; instructions I used for the previous build no longer worked after the Creators Update, so it is possible these may no longer work after the next build.
Here are the high-level steps to know what you are in for:
- Change file ownership of tokens_TTS_en-US.xml, located in *C:\Windows\SysWOW64\Speech_OneCore\Common\en-US*
- Copy and paste a new Voice XML block into the file (full block is on the linked superuser.com page).
- Change file ownership for tokens_TTS_en-US.xml back to original settings.
- Update the registry by importing the Microsoft-Eva-Mobile.reg file (link included on linked superuser.com page).
- Use Process Explorer to identify the correct value to update the registry file MSTTS_V110_enUS_EvaM.reg, and import that file as well (link included on linked superuser.com page).
- Reboot!
Now you will see a new voice option, Microsoft Eva Mobile. If you preview the voice, you will notice it is the same one used by the Cortana assistant.
Text-to-Speech voices after enabling Eva.
Now that we have the voice we want, let’s take a look at how we will use it in PowerShell.
Using SpeechSynthesizer and Cortana in PowerShell
We first we need to use the Add-Type cmdlet to add the System.Speech assembly to our PowerShell session. This allows us to instantiate objects (by using the New-Object cmdlet) and use the objects, just as you would use any .NET Framework object. You see that instantiation below as well.
Add-Type -AssemblyName System.Speech
$SpeechSynthesizer = New-Object System.Speech.Synthesis.SpeechSynthesizer$SpeechSynthesizer is now our object to work with. First, we will set the Voice property to use Eva Mobile, as well as the Rate property to control the speed of the voice.
$SpeechSynthesizer.SelectVoice("Microsoft Eva Mobile")
$SpeechSynthesizer.Rate = 0 # -10 is slowest, 10 is fastestNext, we need to set the object to output the generated audio to a particular WAV file. We do that using the SetOutputToWavFile method of $SpeechSynthesizer.
$WavFileOut = Join-Path -Path $env:USERPROFILE -ChildPath "Desktop\thinkpowershell-demo.wav"
$SpeechSynthesizer.SetOutputToWaveFile($WavFileOut)We are ready to get to the meat of the script, which is the text from which we want to generate the audio file. The simplest way is to create a variable with the text string. Then we use the Speak method to generate the file. You will notice that the file is generated almost instantaneously; you do not have to wait a duration for the string to be “recorded”.
$RecordedText = '
Thank you for trying out the Think PowerShell Text-to-speech demo.
Learn more at thinkpowershell.com.
'
$SpeechSynthesizer.Speak($RecordedText)
$SpeechSynthesizer.Dispose()Now if you go to your desktop, you should be able to open the thinkpowershell-demo-tts.wav file and here it.
Here is the full script:
# Windows 10 Text-to-Speech Example
Add-Type -AssemblyName System.Speech
$SpeechSynthesizer = New-Object System.Speech.Synthesis.SpeechSynthesizer
$SpeechSynthesizer.SelectVoice("Microsoft Eva Mobile")
$SpeechSynthesizer.Rate = 0 # -10 is slowest, 10 is fastest
$WavFileOut = Join-Path -Path $env:USERPROFILE -ChildPath "Desktop\thinkpowershell-demo.wav"
$SpeechSynthesizer.SetOutputToWaveFile($WavFileOut)
$RecordedText = '
Thank you for trying out the Think PowerShell Text-to-speech demo.
Learn more at thinkpowershell.com.
'
$SpeechSynthesizer.Speak($RecordedText)
$SpeechSynthesizer.Dispose()Expanding the Capabilities
This is a basic demonstration, but it provides the basic building block that can be expanded upon.
For example, if you had multiple prompts that needed to be created, you could create a CSV file with the prompt text and the associated file names, then use Get-Content to import the data into your session and use a foreach loop to generate each audio file.
For use cases that require a higher level of manipulation of the voice output, you can replace the simple string variable with an XML formatted string that uses Speech Synthesis Markup Language (SSML) 1.0 specification. You can tweak specific segments of your text using XML tags to adjust pitch, emphasis, and phonetics to name a few. You will use a different method (SpeakSsml) to generate the WAV file. Here is a quick example of how to use it. Reference links are at the bottom of this post related to SSML.
# Windows 10 Text-to-Speech SSML Example
Add-Type -AssemblyName System.Speech
$SpeechSynthesizer = New-Object System.Speech.Synthesis.SpeechSynthesizer
$SpeechSynthesizer.SelectVoice("Microsoft Eva Mobile")
$SpeechSynthesizer.Rate = 0 # -10 is slowest, 10 is fastest
$WavFileOut = Join-Path -Path $env:USERPROFILE -ChildPath "Desktop\thinkpowershell-demo-tts-ssml.wav"
$SpeechSynthesizer.SetOutputToWaveFile($WavFileOut)
$RecordedText = '
<speak version="1.0"
xmlns="http://www.w3.org/2001/10/synthesis"
xml:lang="en-US">
<prosody pitch="low"> I can speak in a low pitch, </prosody>, or
<prosody pitch="high"> I can speak in a high pitch. </prosody>
<prosody rate="slow"> I can talk slow. </prosody>, or
<prosody rate="fast"> I can talk fast! </prosody>
I could say <say-as interpret-as="cardinal"> 2 </say-as> bases, or
I could say <say-as interpret-as="ordinal"> 2nd </say-as> base.
I could say habanero, or I could say
<phoneme alphabet="x-microsoft-ups" ph="H AE . B AX . S1 N J EH lng . R O">
habanero </phoneme>
</speak>
'
$SpeechSynthesizer.SpeakSsml($RecordedText)
$SpeechSynthesizer.Dispose()Next Steps
- Go through the prerequisite steps to enable Cortana on YOUR computer.
- Play around with the SSML capabilities.
- Figure out where you could use this is in your own organization!
Reference
- SpeechSynthesizer Class | msdn.microsoft.com
- Use SSML to Create Prompts and Control TTS | msdn.microsoft.com
- Speech Synthesis Markup Language (SSML) Version 1.0 | w3c.org
- Use Custom Pronunciations (.NET) | msdn.microsoft.com